Qu'est-ce que le RAID ? Origines, Explication, Composants et Configurations
-
 Écrit par Kees Jan Meerman
Écrit par Kees Jan Meerman -
 Mis à jour le Dec 26, 2025
Mis à jour le Dec 26, 2025 -
 Min. En lisant 4 Min
Min. En lisant 4 Min - Partagez ceci
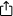
Brève histoire du RAID
Avant que les baies de stockage modernes et les disques Cloud ne deviennent des outils courants, les entreprises étaient confrontées à un défi fondamental : comment stocker de manière fiable et rentable des quantités croissantes de données.
Les systèmes de stockage devaient suivre le rythme des progrès rapides des processeurs et des applications professionnelles de plus en plus exigeantes, mais ils peinaient à y parvenir.
Au milieu des années 1980, tous les centres de données sérieux s'appuyaient encore sur des disques uniques, volumineux et coûteux (SLED).
- Le produit phare d'IBM, le boîtier 3380, pouvait contenir environ 2,52 Go de données, atteignait une vitesse de transfert de 3 Mo/s, avait un temps de recherche moyen de 16 ms et coûtait entre 81 000 et 142 000 livres sterling, sans compter un mètre cube d'espace au sol et un kilowatt d'électricité.

- Les ordinateurs plus petits ne faisaient pas mieux : le premier disque dur pour PC, le ST-506 de 5,25 pouces de Shugart Technology (aujourd'hui Seagate), avait une capacité de seulement 5 Mo et coûtait 1 500 £, soit 300 £ par Mo.

Dans le même temps, la loi de Moore s'appliquait aux processeurs et aux mémoires DRAM de plus en plus bon marché, dont la vitesse ou la capacité doublait tous les 18 à 24 mois, sans changement notable. Cela signifiait que le traitement des transactions, les bases de données SQL et les nouvelles applications client-serveur effectuaient beaucoup plus d'opérations d'E/S aléatoires minuscules qu'un seul axe ne pouvait en gérer.
Des chercheurs de l'université de Berkeley, David Patterson, Garth Gibson et Randy Katz, ont quantifié l'écart : les performances des processeurs augmentaient de 40 % par an, tandis que la latence mécanique d'un disque dur haut de gamme s'améliorait à peine de 7 % par an.
Il en résulta une « crise des E/S » imminente : les processeurs se bloquaient, les fenêtres de traitement par lots dépassaient les délais impartis et les entreprises étaient contraintes de répartir les tables critiques sur des centaines de disques durs SLED.
Cette solution rapide et temporaire a entraîné de nouveaux problèmes.
- Les coûts augmentaient de manière linéaire avec chaque SLED supplémentaire.
- La disponibilité a même diminué, car plus il y avait de broches, plus il y avait de sources de panne.
- Les opérateurs menaient un combat perdu d'avance contre la chaleur, la consommation d'énergie et le manque d'espace.
L'industrie avait un besoin urgent d'un débit et d'une capacité équivalents à ceux des mainframes, mais à des prix comparables à ceux des PC, sans compromettre la fiabilité.
Ce sont précisément ces limitations qui ont inspiré la communauté des chercheurs en stockage dans les années 1980.
RAID : origine et définition
À la fin de l'année 1987, Patterson, Gibson et Katz ont installé une table pliante dans un laboratoire de l'université de Berkeley avec dix disques PC Conner CP-3100 de 100 Mo connectés à un contrôleur SCSI standard.

Ils cherchaient à répondre à la question suivante : un ensemble de disques durs pour PC peu coûteux pouvait-il surpasser le principal ordinateur central de l'époque, l'IBM 3380 ?
Leur publication SIGMOD de 1988, intitulée « A Case for Redundant Arrays of Inexpensive Disks (RAID) », a fourni des preuves tangibles.
| Disque (1987) | Capacité | Vitesse de transfert | Prix/Mo | Performances | Capacité |
|---|---|---|---|---|---|
| IBM 3380 AK4 | 7500 Mo | ≈ 3 Mo/s | 18 | 6,6 kW | 24 pieds |
| Fujitsu « Super Eagle » | 600 Mo | ≈ 2,5 Mo/s | 20 | 64 | 3,4 |
| Conner CP-3100 | 1000 Mo | ≈ 1 Mo/s | 11 | 1 | 0,03 ft |
Ils ont ensuite modélisé une matrice RAID de niveau 5 composée de 100 de ces disques Conner (10 données + 2 parités par groupe).
Résultat :
- Un débit d'E/S, des performances et un gain d'espace environ cinq fois supérieurs à ceux du modèle IBM 3380
- Coût par gigaoctet réduit de deux ordres de grandeur
- Augmentation de la fiabilité calculée grâce à la parité et à la récupération à chaud
En d'autres termes, une matrice d'une valeur de 11 000 £ a atteint, et souvent dépassé, le SLED de 100 000 £ pour tous les indicateurs de performance clés.
Ce tableau a transformé le RAID d'une simple idée en une réalité et a marqué le début de l'ère de la technologie des baies.
Signification du nom « Redundant Array of Independent Disks » (matrice redondante de disques indépendants)
| Mot | Pourquoi est-ce important ? |
|---|---|
| Redondant | Des informations supplémentaires (copies complètes ou codes de parité) sont stockées afin que les données logiques restent en ligne après une panne de disque. |
| Réseau | De nombreux disques physiques sont virtualisés dans un espace d'adressage logique ; le gestionnaire attribue des numéros de bloc hôte aux emplacements des disques/secteurs, commande les E/S et coordonne la récupération. |
| Indépendant (à l'origine « économique ») | Les disques durs standard tombent en panne indépendamment les uns des autres et sont beaucoup moins chers au Go qu'un SLED monolithique. Le contrôleur RAID compense ce taux de défaillance plus élevé, garantissant un MTTDL (temps moyen avant perte de données) plus élevé pour le système. |
| Disques durs | Ce schéma a été développé pour les disques durs rotatifs, mais peut également être appliqué aux SSD et autres disques. |
Un ensemble RAID est donc un disque dur virtuel unique présenté à l'hôte et composé d'un groupe de disques peu coûteux et sujets aux pannes, avec une logique de redondance suffisante pour garantir l'intégrité des données et obtenir des performances globales supérieures.
Avant d'aborder les niveaux RAID spécifiques, nous avons besoin de trois éléments techniques fondamentaux (le striping, le mirroring et la parité) ainsi que de quelques termes de base.
- E/S (entrée/sortie) : toute demande de lecture ou d'écriture émise par l'hôte.
- Hôte : serveur ou entité chargé d'envoyer des demandes de blocs via SAS, SATA, NVMe ou FC.
- Bloc (secteur) : unité atomique (512 octets à 4 kilo-octets) dans laquelle les disques durs stockent les données et les algorithmes RAID calculent la parité.
Grâce à ce vocabulaire, nous pouvons maintenant examiner comment le striping accélère les E/S, comment le mirroring fournit une redondance instantanée et comment la parité nous permet de récupérer les données perdues à l'aide d'une élégante opération mathématique appelée XOR.
Les trois éléments constitutifs du RAID : le striping, le mirroring et la parité
Striping (performances et évolutivité)
Le striping est une technique qui consiste à répartir les données sur plusieurs disques afin qu'ils puissent fonctionner en parallèle. Toutes les têtes de lecture/écriture fonctionnent simultanément sur les disques correspondants, ce qui permet de traiter plus de données en moins de temps. Cela augmente considérablement les performances par rapport à un disque dur unique.
Le diagramme suivant illustre le fonctionnement du striping dans un ensemble de disques W. Une bande est constituée de N blocs contigus sur un disque ; un strip est l'ensemble des bandes alignées qui s'étendent sur W disques (la largeur de bande).
Taille de la bande = taille de la bande × largeur de la bande.
Le choix de la taille des bandes est uniquement une question d'optimisation de la charge de travail. Elle peut être petite (16 à 64 Ko) pour le traitement des transactions en ligne (OLTP) ou grande (256 Ko à 1 Mo) pour les flux vidéo.
En traitant chaque demande d'E/S en parallèle avec plusieurs disques durs, la bande passante séquentielle évolue de manière quasi linéaire avec W jusqu'à ce que le contrôleur ou le bus soit pleinement utilisé.
La configuration RAID avec striping pur (c'est-à-dire sans mise en miroir) est le RAID 0, qui n'offre aucune redondance : si un membre tombe en panne, l'ensemble de la matrice est perdu.
Mise en miroir (redondance immédiate)
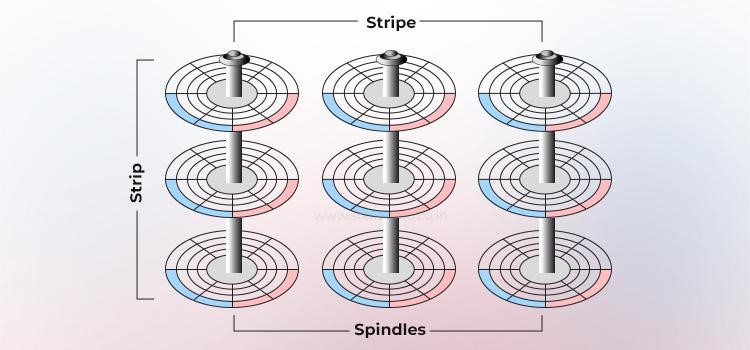
Le miroir est une technique qui consiste à stocker les mêmes données sur deux disques durs différents. Si un disque dur tombe en panne, les données stockées sur le disque dur intact sont entièrement préservées. Le responsable continue à répondre aux demandes de données de l'hôte sans interruption via le membre intact de la paire en miroir.
Lorsque le disque dur défaillant est remplacé par un nouveau, la partie responsable copie automatiquement les données du disque dur intact vers le nouveau disque dur, un processus transparent pour l'hôte.
Dans une configuration RAID en miroir (RAID 1), chaque opération d'écriture est envoyée à au moins deux disques. Cela crée des ensembles de données en double, appelés sous-miroirs. La partie responsable peut effectuer des opérations de lecture à partir du sous-miroir le moins sollicité.
Les systèmes d'exploitation d'entreprise et les adaptateurs de bus hôte (HBA) offrent même des politiques de lecture round-robin ou géométrique pour équilibrer la charge et réduire le temps de recherche.
Bien que la mise en miroir implique une légère latence pour les commandes d'écriture (elles doivent être exécutées deux fois) et que l'efficacité de la capacité soit de 50 %, les avantages l'emportent sur les inconvénients : en cas de défaillance d'un disque, la récupération est simple : il suffit de copier le disque intact sur un disque de remplacement.
Parité (redondance mathématique)
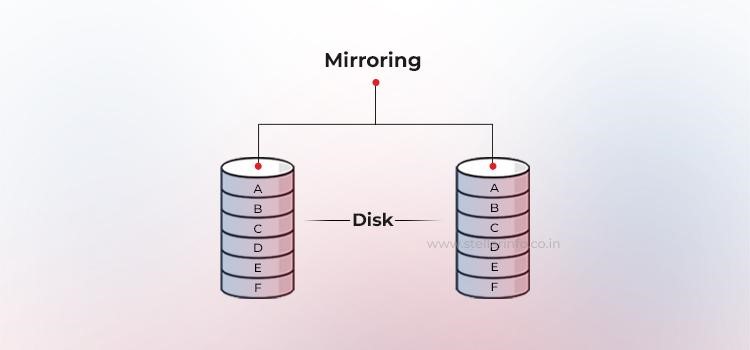
La parité est une méthode qui permet de protéger les données réparties sur plusieurs disques durs contre les pannes de disque dur sans avoir à supporter le coût total de la mise en miroir. Au lieu de dupliquer toutes les données, les matrices RAID utilisent un disque dur supplémentaire (ou un espace de stockage distribué) pour stocker la parité, un résumé mathématique des données qui permet au système de reconstruire les informations perdues.
Cette parité est calculée par le contrôleur RAID à l'aide d'une opération XOR bit à bit sur tous les blocs de données d'une bande. En cas de panne d'un disque, le bloc manquant peut être immédiatement récupéré en effectuant une opération XOR sur les données restantes avec la parité stockée.
Prenons l'exemple de trois bits : A, B et C, où A est la parité générée à partir de B et C. Voici comment fonctionne le XOR :
| B | C | A = B ⊕ C |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Si vous connaissez A et B ou C, vous pouvez toujours récupérer le troisième élément. C'est le principe de parité utilisé par le RAID pour récupérer les blocs de données manquants.
Les informations de parité peuvent être stockées sur un disque dur dédié (RAID 4) ou réparties sur tous les membres (RAID 5). Le RAID 6 va encore plus loin et ajoute un deuxième bloc de parité, permettant ainsi la récupération des données en cas de deux pannes simultanées. L'inconvénient est une petite surcharge d'écriture : à chaque mise à jour, les données d'origine et la parité sont modifiées, ce qui nécessite des cycles de lecture, de modification et d'écriture supplémentaires qui ont un impact sur les performances.
Le RAID est un cadre : chaque niveau résout un problème différent
La publication de Berkeley en 1988 a donc fait plus que simplement inventer un acronyme : elle a défini un cadre pour faire évoluer les systèmes de stockage selon trois axes : les performances, l'efficacité de la capacité et la tolérance aux pannes.
- Le striping pur sans redondance est devenu le RAID 0.
- L'ajout d'une duplication complète a donné naissance au RAID 1, qui privilégie la disponibilité plutôt que les téraoctets utilisables.
- En combinant le striping et la parité mathématique, on obtient les configurations RAID 5 et 6, qui sacrifient une partie de la vitesse d'écriture pour survivre à la défaillance d'un ou même de deux disques.
Chaque configuration correspond simplement à un point différent dans l'espace enregistré par le document SIGMOD de 1988.
Lisez d’autres articles pour approfondir vos connaissances sur le RAID et la récupération de données :


À propos de l'auteur
Managing Director, Stellar Data Recovery Europe



